
Abstract
Text-to-image (T2I) diffusion models rely on encoded prompts to guide the image generation process. Typically, these prompts are extended to a fixed length by adding padding tokens before text encoding. Despite being a default practice, the influence of padding tokens on the image generation process has not been investigated. In this work, we conduct the first in-depth analysis of the role padding tokens play in T2I models. We develop two causal techniques to analyze how information is encoded in the representation of tokens across different components of the T2I pipeline. Using these techniques, we investigate when and how padding tokens impact the image generation process. Our findings reveal three distinct scenarios: padding tokens may affect the model's output during text encoding, during the diffusion process, or be effectively ignored. Moreover, we identify key relationships between these scenarios and the model's architecture (cross or self-attention) and its training process (frozen or trained text encoder). These insights contribute to a deeper understanding of the mechanisms of padding tokens, potentially informing future model design and training practices in T2I systems.
Key Insights
- Training Process Matters:Models with frozen text encoders (e.g., Stable Diffusion) tend to ignore padding tokens, while those with trainable text encoders (e.g., LDM and LLaMA-UNet) don’t.
- Architecture Matters:Multimodal attention architectures (e.g., FLUX, Stable Diffusion 3) can encode meaningful information in unused padding tokens during diffusion. Attention maps show these tokens may store details vital for nuanced visual generation.
- Proximity to Prompt Matters:Padding tokens closer to prompt tokens encode more significant information. This suggests the role of positional encoding or causal masking in how padding tokens function, especially in models like LLaMA-UNet.
- The text-encoder is being finetuned (not frozen), or -
- The architecture is diffusion transformer (and not diffusion UNET).
Analysis of Padding in Text Encoding
Method
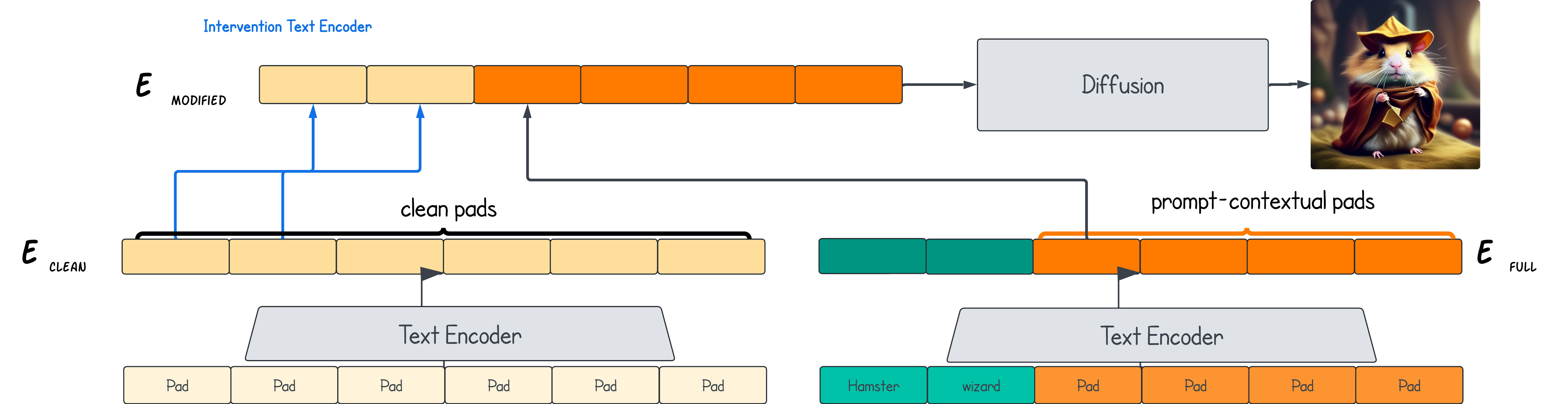
By analyzing modified versions of the full text embedding, we isolate the effects of padding tokens on the final output. This approach allows us to visually showcase the distinct contributions of prompt tokens versus padding tokens. To achieve this, we replace specific tokens in the prompt with "clean" padding tokens—neutral placeholders that contain no information from the original prompt. By comparing images generated from the full representation and its variations, we illustrate how much information is carried by the padding tokens. The following figure demonstrates this process, highlighting the nuanced interplay between padding and prompt tokens in shaping generated images.

Results
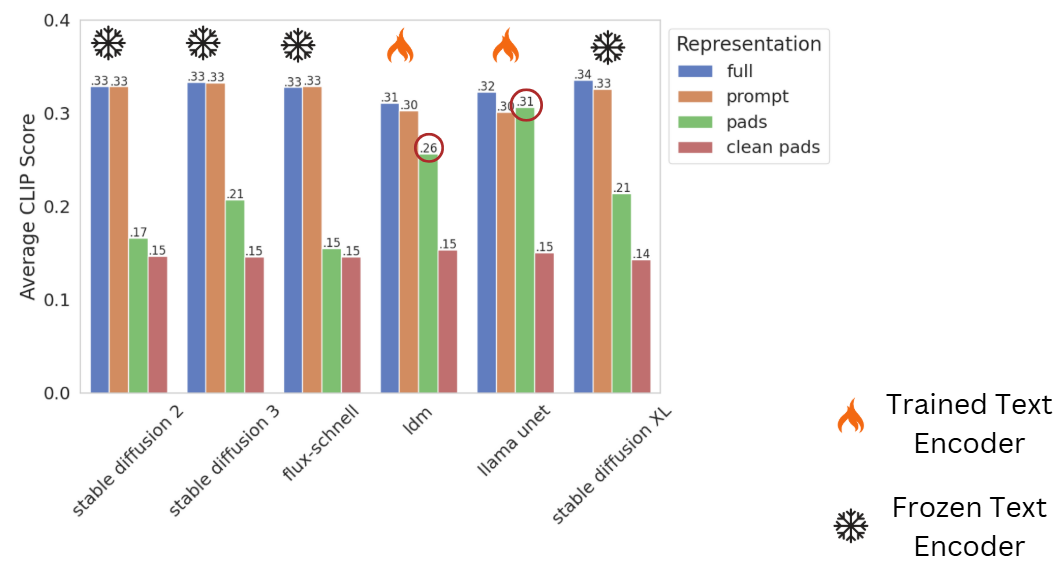
The way a text encoder is trained has a significant influence on how padding tokens are handled during image generation. In many current T2I models, such as Stable Diffusion and FLUX, the text encoder is frozen, meaning it is not fine-tuned for the image generation task. Consequently, padding tokens, which are not explicitly trained to contribute meaningfully to the encoded representation, have little to no impact on the generated images.
For instance, as shown in our results, images generated using contextualized padding only in these models yield low CLIP scores, comparable to those generated with clean padding.
In contrast, models like LDM and Lavi-Bridge adapt the text encoder specifically for image generation by training it on the task, including the effective use of padding tokens. This adaptation enables the text encoder to learn meaningful representations for padding tokens, with higher CLIP scores for images generated from padding only.
In the fine-tuned models, we also observe a slight degradation in CLIP score when generating an image from the prompt only, indicating that meaningful information is encoded in the padding tokens.
The following figure illustrates how the finetuning process contributes to the role of padding tokens: as we interpolate the scaling factor for the LoRA weights, we see the increased role of the padding tokens.

Analysis of Padding in Diffusion Process
Method
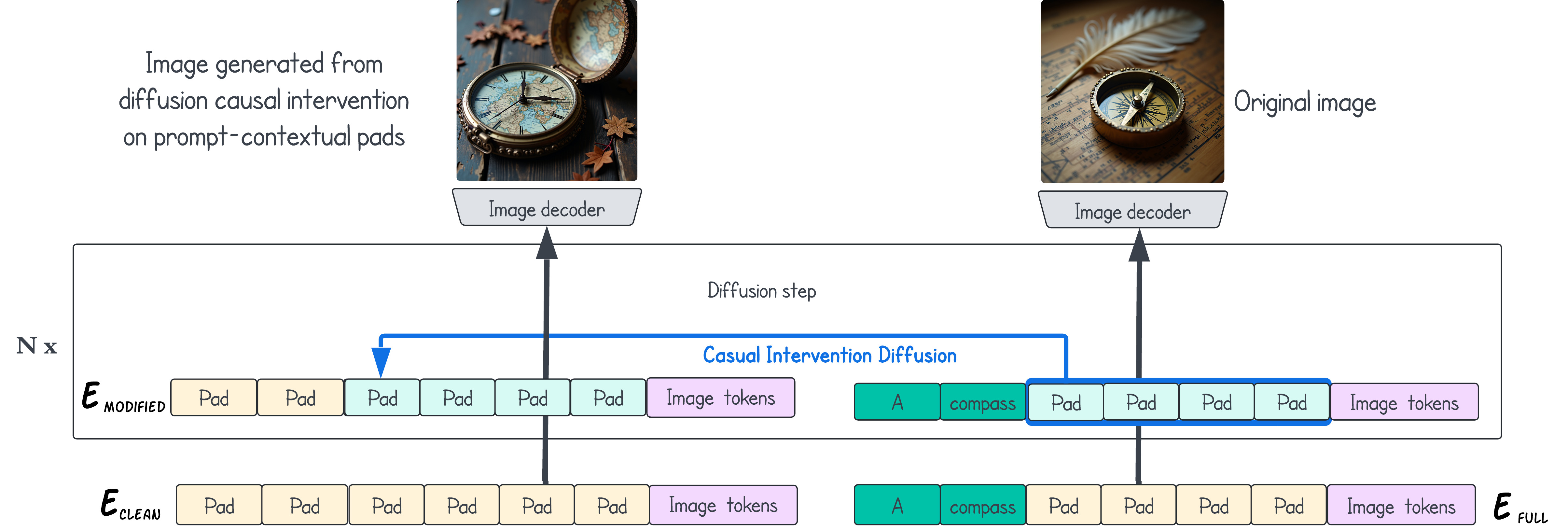
Padding tokens can also play a role in the diffusion process of T2I models, where models have either cross-attention or multi-modal self-attention. Cross-attention, as seen in Stable Diffusion 2/XL, keeps text representations static while using attention maps to transfer information from text to image patches. In contrast, MM-DiT blocks in models like FLUX and Stable Diffusion 3, allow both text and image representations to dynamically influence each other, potentially embedding additional information, even into padding tokens. This distinction raises questions about the use and significance of padding tokens across different attention mechanisms.
To investigate, we analyze the attention maps between image patches and text tokens. We further perform a causal analysis where we patch clean padding tokens into the contextual padding tokens, as seen in the figure above.
Results
Our findings reveal that while Stable Diffusion XL focuses attention primarily on meaningful tokens, attention maps for FLUX diffusion show strong alignment between prompt tokens and semantically relevant image tokens. These maps also reveal high attention for padding tokens with the main objects in the image.
Qualitative experiments further showed that removing padding tokens in FLUX often resulted in missing image details, while Stable Diffusion XL maintained consistent output. These insights suggest that models using MM-DiT blocks might leverage padding tokens as temporary storage to pass information during the diffusion process, similar to how vision-language models handle image patches.

How to cite
bibliography
Michael Toker, Ido Galil, Hadas Orgad, Rinon Gal, Yoad Tewel, Gal Chechik, Yonatan Belinkov, “Padding Tone: A Mechanistic Analysis of Padding Tokens in T2I Models”.
bibtex
@misc{toker2025paddingtonemechanisticanalysis,
title={Padding Tone: A Mechanistic Analysis of Padding Tokens in T2I Models},
author={Michael Toker and Ido Galil and Hadas Orgad and Rinon Gal and Yoad Tewel and Gal Chechik and Yonatan Belinkov},
year={2025},
eprint={2501.06751},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.06751},
}